人-物交互理解[1,2]在计算机视觉与机器人领域有重要的意义,让人工智能算法理解三维空间下复杂的人与物体交互一直是研究者们追求的目标。然而,这一目标的实现还面临诸多挑战。
首先,学术界缺少一个针对全身参与的人与复杂物体交互理解的算法。现有方法大多限制在与刚体的交互[3,4],或仅关注某个特定的身体部位。其次,真实环境下的物体结构复杂,难以用一个单一的模板来描述。近期,学界开始对带自由度的物体[5]进行研究,但仍仅限于一个可动部件,缺少复杂的结构和运动方式。第三,对人与物体之间关系的建模也是现阶段的一大挑战[6]。以人与椅子的交互为例,当身体向后靠时,椅子靠背会产生旋转。类似的这种现象里面包含了复杂的人与物体间三维结构相关性。上述几大挑战并非不可实现,但根本问题均指向了算法先验知识的不足。
近日,北京大学人工智能研究院朱毅鑫助理教授,与北京通用人工智能研究院(通院)黄思远研究员在ICCV 2023会议联合发表以“Full-Body Articulated Human-Object Interaction”为题的论文。该研究的目标是复杂人-物交互理解的问题,文章提出了利用全身交互三维先验进行细粒度人-物体交互理解与重建的算法,并展示了下游视觉相关任务的应用;文章同时提出了基于大量人与带自由度的铰接物体交互片段的交互先验,并提供了精细的三维姿态和结构标注的真实数据。这些真实数据来源于大量的真实交互案例,包含总长为17.3小时的人与复杂物体交互的片段、46位不同的拍摄人员、81把形状结构不同的椅子、沙发和板凳交互物体等,提供了精细的人体和物体的三维形状信息标注。同时附带多视角RGB和深度的拍摄原始数据信息,以及匹配校准后的点云数据。基于CHAIRS数据集,文章还针对人-物交互理解的任务,提出了使用cVAE模型训练的人-物交互先验来指引物体部件重建和姿态优化的过程,实现带自由度关节参数的准确估计和人体-物体联合三维重建。

CHAIRS数据集示例,包含人与带活动关节物体的三维交互捕捉
研究主要解决了从单张图片中重建人-物交互的问题。其中:
人体用SMPL-X参数来表示。如果给定物体模型,用6D位姿表示物体的每个部分,不给定模型的情况下则直接对物体进行三维重建。物体重建模型以图片和估计的人体姿态为输入,提取图片特征以及人体在不同尺度下的体素,将图片特征输入至三维反卷积网络,并将每层的三维特征拼接人体体素信息,最终得到空间中的点被物体占有的概率分布。
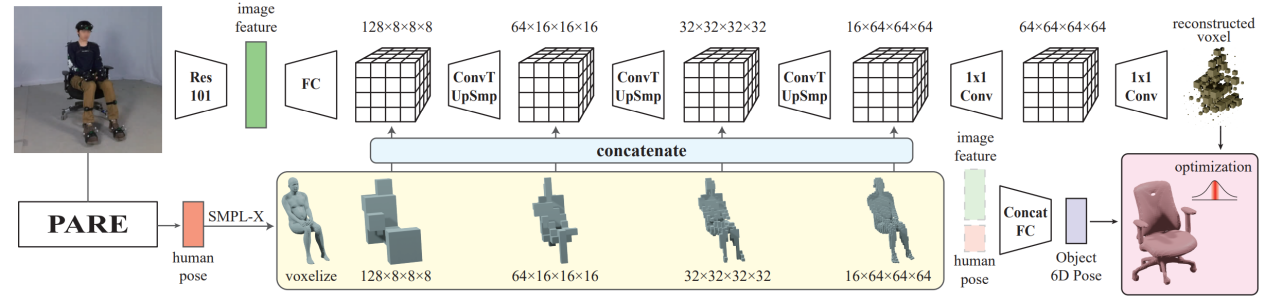
人-物交互重建模型架构
细粒度关系的建模对人-物交互的理解有重要价值。本文提出基于cVAE的交互先验模型,从CHAIRS的大量交互数据中学习了在给定人体姿态下的物体三维空间分布。交互先验模型以体素化的人体作为输入,输出周边空间内每个点被占有情况的联合概率分布。这种建模方式可以在已估计出人体姿态的情况下,得出最有可能的物体形状,以此来对物体姿态估计提供必要的指引。
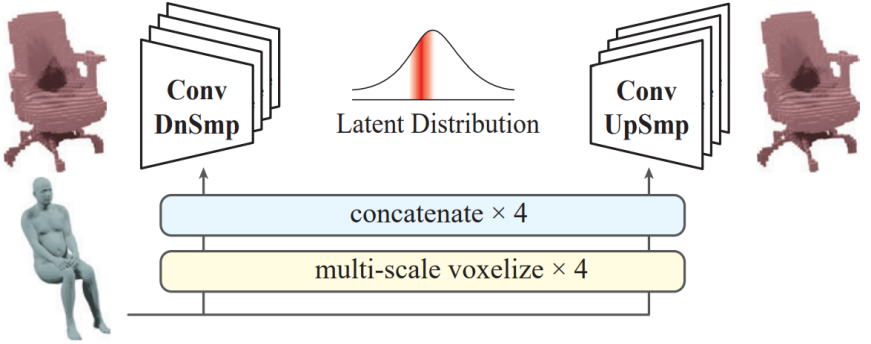
人-物交互先验图示
实验环境设置:所有片段都在一个装有惯性-光学混合动作捕捉系统的区域中采集,所有动作对摄像头完全可见。周边设置了四个面向人物的多视角Kinect Azure DK相机,经过了精确校准和同步,以获取RGB-D信息以及点云。
物体姿态的收集:首先,将物体排列到其初始的姿态,并将混合追踪器附着到其每个可移动部分。在记录交互的过程中,根据追踪器的姿态实时计算每个物体部分的基准6D姿态。最后,将刚性部分拟合到物体的运动结构以获得高质量的物体姿态。
人体姿态和形状的收集:采用SMPL-X表示法来表示人体姿态和形状。参与者在录制过程中穿上带有17个IMU、一双手套和5个安装在头、手和脚上的混合追踪器的动作捕捉套装。交互过程中优化人体模型的形状参数,使得重构的SMPL-X网格与混合追踪器的位置对齐。动作捕捉系统在记录过程中实时产生人体姿态和形状的估计。

动作捕捉设置及实验室配置
为全方位评估研究方法的效果,研究团队使用CHAIRS数据集以及网络中包含人和椅子的图片测试了人-物交互重建。实验结果显示,不论是否给定物体的三维模型,本文提出的方法均能基于单张图片重建出合理的人体和物体的交互姿态。研究填补了三维视觉领域在全身复杂交互方法的空白,为可供性、具身智能等算法的研究与落地奠定了基础。

人-物交互重建结果示例
论文第一作者为北京大学博士生蒋楠、通院刘腾宇研究员,通讯作者为朱毅鑫、黄思远。论文作者还包括清华自动化系本科生曹哲瑄和张至远、通院实习生崔洁茗、通院研究员陈以新和北京大学助理教授王鹤。
参考文献
[1] Zhu Y, Jiang C, Zhao Y, et al. Inferring forces and learning human utilities from videos. In Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Chen Y, Huang S, Yuan T, et al. Holistic++ scene understanding: Single-view 3d holistic scene parsing and human pose estimation with human-object interaction and physical commonsense. In International Conference on Computer Vision (ICCV), 2019.
[3] Taheri O, Ghorbani N, Black M J, et al. GRAB: A dataset of whole-body human grasping of objects. In European Conference on Computer Vision (ECCV), 2020.
[4] Bhatnagar B L, Xie X, Petrov I A, et al. Behave: Dataset and method for tracking human object interactions. In Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
[5] Fan Z, Taheri O, Tzionas D, et al. ARCTIC: A Dataset for Dexterous Bimanual Hand-Object Manipulation. In Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
[6] Zhang J Y, Pepose S, Joo H, et al. Perceiving 3d human-object spatial arrangements from a single image in the wild. In European Conference on Computer Vision (ECCV), 2020.


