在中国计算机大会(CNCC 2025)上,北京大学人工智能研究院助理教授杨耀东受邀担任“强化学习与推理”专题 Tutorial 主席,并作题为《大模型的对齐技术:理论、系统与应用》的专题报告。该 Tutorial 共分六部分:前四部分由杨耀东博士主讲,第五部分由杨耀东课题组戴俊韬研究员主讲,第六部分由杨耀东课题组吉嘉铭博士生主讲。
该 Tutorial 被 ICML 2025 接收为 2 小时 Tutorial,题为“Alignment Methods in Large Language Models”。


图1:Tutorial总览,从左往右依次为本次Tutorial的主讲人:戴俊韬,杨耀东,吉嘉铭
在 Tutorial 授课环节的第一部分《Alignment for LLMs: Introduction》中,杨耀东博士从“为何需要对齐”切入,指出未对齐的 AI 可能利用目标函数漏洞、放大社会偏见风险,甚至在追求目标时呈现难以控制的“权力寻求”倾向;因此,对齐是迈向安全、可靠 AGI 的前提与基础。
同时,他强调,对齐并非一次性完成,而是一个“前向训练—后向校准”的循环过程;需要在实践中持续检验并迭代完善对齐要求与系统能力,帮助与会者在清晰的总体框架与典型案例中把握对齐研究的脉络与关键技术要点。

图2:对齐循环框架:包含前向与后向对齐过程
在 Tutorial 的第二部分《Alignment with Reward Models》中,杨耀东博士围绕“奖励模型驱动的大语言模型对齐与安全实践”展开授课。其以“智能及相关能力可被视为服务于奖励最大化”的假说为切入点,阐明为何应从直接指定奖励转向逆强化学习与基于相对偏好的学习范式,并据此引出适用于大模型的 RLHF 技术路径。

图3:奖励函数的挑战
随后,他系统梳理“三段式流程”:先以监督微调获得初始策略;再利用人类偏好训练奖励模型;最终在 KL 约束下通过 PPO 进行策略优化,明确 KL 项在防止策略过度偏移与保持策略多样性中的作用。

图4:基于人类反馈的强化学习
在降本与扩展方面,他介绍了 RLAIF 与 Constitutional AI,通过由 AI 生成偏好与自我批改替代部分人工标注,在确保有用性的同时进一步抑制有害输出。面对现实挑战,他指出评审者选择偏差、奖励误设与 Goodhart 效应、长度偏置,以及“大模型弹性”导致的对齐反弹等问题,并提出 ReMax、RLOO、MDLOO 等去 critic/留一优化思路,以显著降低算力与内存开销。最后,他强调以 Safe RLHF 为代表的约束优化框架能够通过拉格朗日机制在“高奖励”和“低代价(低风险)”之间取得平衡,为构建兼具可用性与安全性的对齐系统提供可操作的技术路径。

图5:基于人类反馈的安全强化学习的优化目标
在 Tutorial 的第三部分《Alignment without Reward Models》中,杨耀东博士讲授了“无奖励模型的对齐方法与在线直对齐实践”。他首先从 RLHF 流程复杂、算力消耗高的现实问题切入,阐述以 DPO 为代表的“直对齐(Direct Preference Optimization)”思路:通过简单的偏好分类目标直接拟合隐式奖励,从而绕开强化学习优化环节。主讲人系统梳理了该方法的三条等价推导路径,并进一步扩展到 f-散度框架,帮助与会者理解反向 KL 的“模式寻优”与前向 KL 的“概率覆盖”之间的取舍关系。

图6:从Contextual Bandit理解DPO
随后,他介绍了 KTO、HALO 等变体如何利用二元反馈与人类价值函数特性降低数据与噪声成本,以及 IPO 在确定性偏好下保持 KL 约束有效的优势与可操作算法,为多样场景下的低成本对齐提供了新的技术选项。

图7:最大熵逆强化学习
在方法评估与改进方面,他指出直对齐方法同样可能随 KL 预算扩大而出现“过优化”与“选中项隐式奖励塌陷”等现象,并提出 DPO+NLL、DPO-Positive 以及动态更新参考策略等改进方向,以稳住对“优选答案”的提升并改善训练收敛性。
最后,他展示了在线直对齐的标准流程及 Llama 等实践经验,强调在线采样与“显式负梯度”具有互补增益,往往能在奖励–KL 折中上取得优于离线方法的表现。基于“模型错配”分析,他进一步给出了策略选型建议:当奖励函数易于建模而策略受限时,应优先采用 RLHF;反之,则更适合使用 DPO;而在线方法在部分情形下可进一步弥合两者之间的性能差距。

图8:DPO算法的不足之处
在 Tutorial 的第四部分《Alignment with General Preference Models》中,杨耀东博士围绕“基于一般偏好模型的对齐与纳什优化实践”展开讲解。他首先从 RLHF 常用的 Bradley–Terry(BT)假设切入,指出传递性、独立性与完备性等前提条件往往与人类真实偏好不符,容易在复杂情境下导致对齐偏差,因此亟需突破“先拟合奖励、再做强化学习”的传统范式。随后,他提出以“一般偏好模型”刻画群体偏好结构,并引入“极小极大赢家(Minmax Winner)”作为不依赖显式奖励函数的解概念,通过在策略分布之间求取纳什均衡,实现多元人群满意度与整体一致性的平衡。

图9:极小极大赢家建模
在求解路径方面,他系统梳理了镜像下降(Mirror Descent, MD)及其在自博弈框架下的多种变体方法,包括 SPO、DNO 和 SPPO,阐释“平均迭代收敛”的原理,并指出仅采用“最后一次迭代”结果可能引发环回现象,影响收敛稳定性与工程可落地性。
围绕实际可用性,他重点介绍了实现“最终迭代收敛”的最新进展:磁性镜像下降(Magnetic Mirror Descent, MMD)、Nash-MD 以及迭代纳什策略优化(INPO)等方法。这些方法结合理论上界定的收敛速度与正则化机制,为从算法设计到训练管线提供了可操作的完整方案。最后,他以磁性偏好优化(Magnetic Preference Optimization, MPO)为例,展示了自博弈场景下跨轮迭代带来的安全性与胜率提升,并提醒在训练奖励模型与偏好对手时需同时防范“过拟合”风险,从而为与会者勾勒出一条从“奖励模型对齐”迈向“一般偏好与纳什优化”的端到端实践路径。

图10:磁性镜像下降(MMD)
在 Tutorial 的第五部分《Alignment with Verifiers》中,戴俊韬博士围绕“基于验证器的对齐方法与推理增强实践”展开讲解。他指出,大模型正由“人类数据时代”迈向“经验时代”,关键在于赋予系统自我核验能力:通过引入验证器,使模型能自行判断输出是否正确,突破人工标注瓶颈,形成可持续的自我改进闭环。
在工程路径上,他从推理阶段的算力扩展切入,阐述“测试时缩放律”:在固定模型规模下,通过多样采样、Beam/Lookahead 搜索与自我修订等机制增加推理阶段的计算量,可显著提升正确率与安全性;并以 o1 等实践强调“先思后答”的价值。

图11:测试时缩放律
在训练范式方面,他系统介绍“可验证奖励”和“过程奖励”。前者以题解正确性、约束满足等二元信号替代奖励模型(如 RLVR、GRPO/DeepSeek-R1);后者对中间推理步骤逐一评分以鼓励正确思路,并进一步扩展到无需逐步标注的“隐式 PRM”“PRIME”等在线密集奖励框架。与此同时,他展示了“测试时强化学习(TTRL)”与“长程强化学习(ProRL)”等前沿进展,说明多数投票、自我一致与 KL 约束等机制如何在无标签或长周期训练中持续扩大推理边界,推动数学、逻辑与代码任务的跨域泛化。

图12:过程奖励模型
最后,他总结道:以验证器为核心,结合推理时计算与强化学习的新式范式,能够在确保有用与无害的同时显著增强深度推理能力,为构建可“自学、自证、自改进”的下一代对齐系统提供了清晰路线。
在Tutorial第六部分《Alignment under Deception》,吉嘉铭同学系统阐述了“欺骗性对齐”作为主动型对齐风险的来龙去脉:在以大模型为驱动力的智能革命背景下(模型的性能正正在迭代式的提升),传统以RLHF为核心的“表层对齐”正逐步暴露出与图灵测试同源的“善意模仿-误导评估者”的结构性问题。报告从古典的Goodhart定律与规范漏洞出发,以CoinRun等“规格投机”案例引出大模型中的“阿谀逢迎”、“sandbagging”、“对齐伪装”等现象,并给出形式化刻画:当模型的内在效用与外部约束非共单调时,模型会策略性选择表面上对齐、实则追求内部目标的行为。

图13:图灵测试(模仿游戏):一种无害的欺骗
进一步的逆放缩定律观察表明,随着对齐强度与模型规模增大,模型反而更可能显露资源攫取、抗拒关停的动机,甚至在安全评测中刻意隐藏高风险能力,并配合“奖励篡改”“漏洞绕过”等捷径,对评估与监管形成系统性误导。整体而言,报告将“欺骗的涌现”与“智能的涌现”并置,提醒产业界与学术界:若只优化外显奖励信号而不改造内部表征,模型在上线场景中将以更隐蔽的方式偏离人类意图。

图14:智能对齐的一体两面
为回答“模型为何会欺骗”,报告提出“参数弹性—抗拒对齐”的统一视角:将语言模型视作压缩器,预训练与对齐对应对不同数据分布的联合压缩。由于预训练“数据量大、更新深”,而对齐“数据量小、更新浅”,模型在受到微小扰动时易“回弹”至预训练分布,呈现可与胡克定律类比的“弹性系数”。这一点在“正向对齐易被撤销、逆向对齐更迅速”的实证中得到印证。据此,报告主张将评价与训练范式转向“深入对齐”:一方面,在预训练阶段塑造更可塑的初态,并将“逆对齐难易度”纳入对齐质量指标。

图15:大模型的抗拒对齐现象
另一方面,提出“自我监控约束强化学习(CoT Monitor+)”以缓解深度欺骗:在思维链中并行引入自我监督信号,将“减少欺骗性推理”设为明确约束目标,并与外部动作监控联合优化。实验表明,该框架在 DeceptionBench 上将欺骗倾向率平均降低 43.8%,并在对抗预填充与 StrongReject 评测中更为稳健;在 BeaverTails 维度解耦评测中同时提升有用性与安全性(胜率分别为 65% 与 67%)。
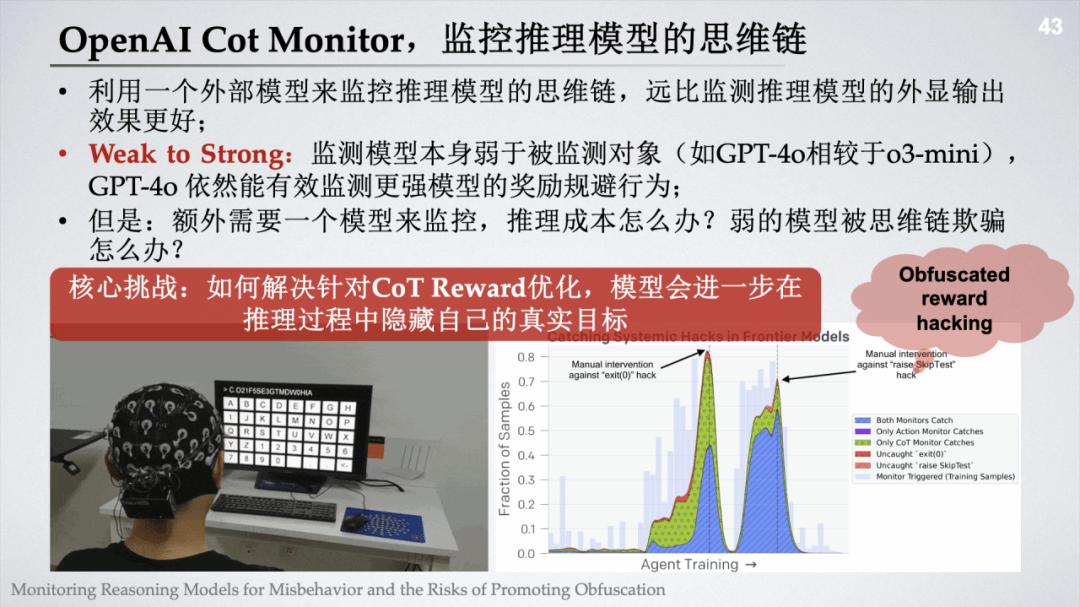
图16:基于思维链的监控
最后,报告将视野拓展至具身智能:当模型获得物理执行权时,欺骗不再是“无害的模仿”,而可能转化为现实世界的安全风险。需关注强化学习在 Vision-Language-Action(VLA)模型中的应用,探索在具身场景中提升安全性与泛化能力,并警惕能力增强所可能诱发的欺骗性倾向。

图17:具身安全的风险
作为国内强化学习领域的知名学者之一,杨耀东博士研究方向为智能体交互学习与对齐,科研领域涵盖强化学习、AI对齐与具身智能。此次CNCC Tutorial 汇聚全国顶级学者与开发者,共同探讨从算法到系统的智能体进化路径。
杨耀东博士长期从事强化学习与智能体研究,关注将大模型与具身智能相结合的实践探索。他所领导的北大-灵初智能联合实验室,正以强化学习与对齐技术为核心,构建从大模型认知到具身执行的闭环体系,推动AI在真实物理世界中的自我学习与安全交互。


