在人工智能向神经符号融合发展的浪潮中,概率电路作为可处理概率模型的核心代表,凭借参数高效性和强大的概率推理表达能力,成为解决精确推理问题的关键技术。然而,概率电路的稀疏有向无环图结构带来了严重的稀疏 - 并行性鸿沟,现有 GPU 基于块稀疏的计算方式存在大量计算空位,传统 DAG 处理单元又无法利用节点重复特性,导致吞吐量低下。
为解决这一问题,北京大学人工智能研究院团队联合新加坡国立大学、加州大学洛杉矶分校等机构的研究团队提出了ESTroM 元素流架构,为稀疏可处理概率模型打造了专用加速方案。该成果发表于 2026 年于澳大利亚悉尼召开的 IEEE Symposium on High-Performance Computer Architecture(HPCA)会议,不仅完成了 28nm 工艺的芯片流片验证,还构建了端到端的神经无损压缩演示系统,在性能、效率和实际应用上实现多重突破,为概率人工智能的高性能计算开辟了硬件新路径。
概率电路由输入节点、和节点、积节点三层核心节点构成,输入节点定义单变量原子分布,积节点通过乘法捕捉变量间的因子化依赖,和节点通过加权平均实现混合建模,三者按 DAG 拓扑结构层级聚合,最终构建复杂的概率分布。为进一步提升计算效率,概率电路引入隐变量并将节点分组为节点块,通过剪枝形成结构化稀疏—— 仅保留部分节点连接,既减少了参数数量、防止过拟合,又能表示高维分布。

图表 1 稀疏概率电路的DAG结构
但稀疏性也带来了新的矛盾:不规则的连接模式使计算具有强数据依赖性,难以实现硬件友好的并行化;而稠密的概率电路虽能利用规则连接实现并行,却会导致参数膨胀,这一矛盾成为概率电路加速的核心难点,形成了典型的稀疏 - 并行性鸿沟:稀疏性虽能减少总运算量,但端到端计算延迟的下降速度却远低于预期。
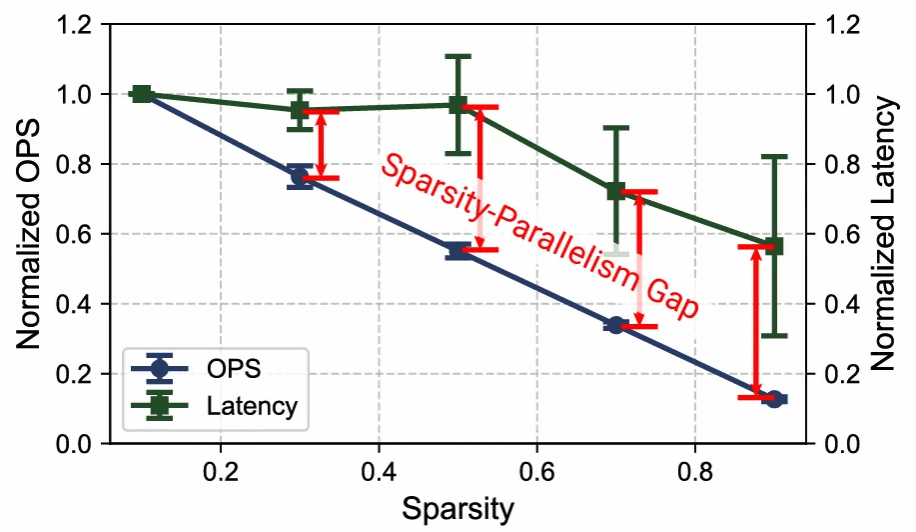
图表 2 稀疏度-并行鸿沟
ESTroM 架构的核心是图元素并行性和元素流执行,通过压缩矩阵表示稀疏 DAG、专用核心处理不同节点、优化数据路径和部署流程,实现了稀疏概率电路的高效加速,同时完成了芯片原型设计和系统优化,形成了从架构到硬件再到应用的完整解决方案。
1. 核心基础:图元素并行性与压缩矩阵表示


图表 3 加节点和乘节点的编码方式
ESTroM将隐变量纳入概率电路的软硬件协同设计,提出图元素并行性策略,将概率电路 DAG 分解为和节点、积节点两个独立计算组,针对二者的计算特性采用差异化并行方式:积节点基于边并行,和节点基于节点并行,并通过压缩矩阵实现 DAG 的稀疏表示。压缩矩阵同时存储模型结构信息和参数,针对和、积节点设计差异化编码方式:
积节点(和到积连接):无参数,压缩矩阵仅存储子节点 ID,利用概率电路语义保证同一节点块内所有积节点的入度相同,简化计算;
和节点(积到和连接):带权重参数,压缩矩阵存储子节点 ID、边数和对应参数,类比神经网络的乘积累加,适配稀疏加权求和计算。
2. 核心架构:ESTroM元素流硬件架构
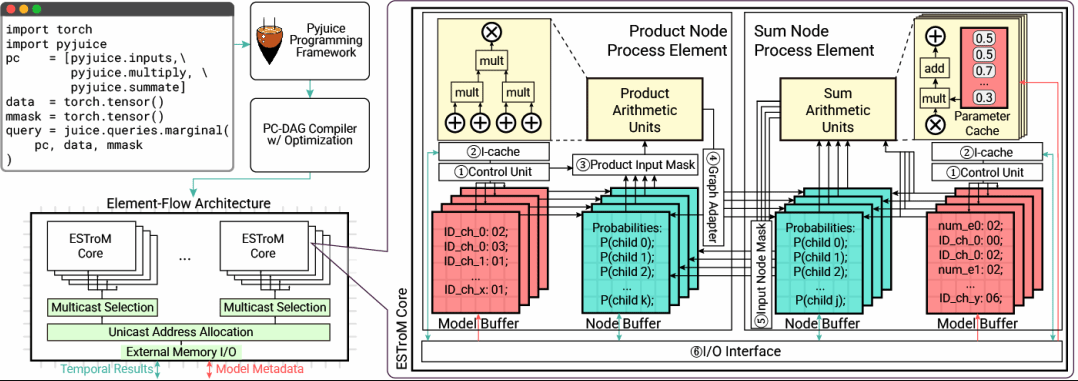
图表 4 ESTroM核心架构
ESTroM 架构由多个ESTroM 核心构成,核心内部集成积节点处理单元(PAU)、和节点处理单元(SAU),并设计分层的本地存储、专用算术单元和控制单元,实现 “边流” 处理积节点、“节点流” 处理和节点的元素流执行模式,同时兼容 PyJuice 编程框架,实现软硬件协同。每个核心包括:
2.1. 本地存储层:包含节点缓冲区、模型缓冲区、参数缓存和指令缓存,最大化数据复用,减少昂贵的外部内存访问。
2.2. 专用算术单元:针对和、积节点的计算特性定制,实现高效并行计算:
o 积节点算术单元(PAU):采用乘法树结构,支持多输入并行乘法,通过 “边流” 将积节点的边输入至 PAU 并行计算,适配因子化乘法需求;
o 和节点算术单元(SAU):由乘加算子和参数缓存构成,将不同节点的边并行化,利用稀疏矩阵特性实现内部稀疏性利用,通过 “节点流” 将和节点输入至 SAU 执行稀疏加权求和。
2.3. 辅助控制单元:包含控制单元、输入掩码、图适配器、I/O 接口等,实现指令解析、数据选择、地址分配和外部交互。
3. 关键优化:部署流程与数据路径优化
概率电路DAG结构的复杂性,导致硬件执行中容易产生流水线气泡,带宽开销问题。ESTroM设计了专属的部署流程和数据路径优化技术,提升架构的兼容性和并行效率:
3.1. 分层部署流程:
将概率电路划分为 “切片”(由一个和节点块及关联积节点块构成),按拓扑排序后部署至 ESTroM 核心,支持单核心和多核心协同部署 —— 单核心可存储完整和节点块时直接并行执行,超出核心容量时将节点块拆分至多个核心,通过多播实现数据共享。
3.2. 两大核心优化技术:
o 核内回卷(Intra-ESTroM-core rewind):解决积节点边数超过 PAU 并行性的问题,通过图适配器将 PAU 的中间结果回卷至节点缓冲区,避免额外的外部内存访问,消除流水线气泡;

o 核间多播(Inter-ESTroM-core multicast):在 I/O 接口添加多播选择位,将顶层地址分为单播地址和多播选择位,实现多个核心的同步数据写入,减少节点块拆分时的重复数据传输,大幅降低带宽开销。

图表 6 核间多播的优化
研究团队从消融实验、基准性能、实际应用三个维度对 ESTroM 架构进行了全面评估,测试基于 28nm 工艺的 RTL 设计,时钟频率 500MHz,对比当前最先进的 DAG处理器(DPU)、GPU、CPU,ESTroM 在性能、能效、压缩效果等方面实现全方位领先。
1. 消融实验:核心优化的有效性

图表 7 ESTroM相较DAG处理方式的消融实验结果
针对图元素并行性和各类优化技术的消融实验表明,ESTroM 的核心优化策略能显著降低计算延迟:
1.1. 模型 / 节点缓冲区的数据复用:平均带来 1.56× 的速度提升,隐变量数量和批处理量越大、积节点边数越小,数据复用收益越高,最高可达 2.02×;
1.2. PAU/SAU 的内部并行性:平均带来 1.63× 的速度提升,隐变量数量和批处理量的增加能显著提升并行收益,最高可达 1.88×;
1.3. 核内回卷 + 核间多播:有效减少内存停滞和流水线气泡,平均降低带宽需求 0.44×;
整体而言,与同配置的 DAG 风格处理相比,ESTroM 的元素流并行技术平均实现2.56× 的速度提升,提升范围达 2.11~3.79×。
基准性能测试中,在 HCLT、SPN 等典型概率电路模型的推理测试上,ESTroM 展现出明显的性能优势。
与 DPU-v2相比,ESTroM 在面积效率和功耗效率上实现双重突破,面积效率达到其16.8×;能效达到其1.9×。
同时,ESTroM 的功耗仅 10.7W,远低于 GPU 的 273.3W,在高性能的同时实现了高能效。

图表 8 基于ESTroM的无损压缩演示系统
基于 ESTroM 原型芯片,研究团队构建了端到端的 PC 基神经无损压缩系统,在 ImageNet64 数据集上的测试结果显示,基于ESTroM的压缩方式,全面超越标准无损压缩算法 Zstd:相比 Zstd 最高压缩级别(lvl-22),实现1.39× 的压缩比提升;相比 Intel Xeon Gold 6230 CPU 上的Zstd压缩速度,ESTroM实现了16.3× 的速度提升。
ESTroM 作为专为稀疏可处理概率模型设计的元素流架构,通过图元素并行性的创新理论,首次实现了和节点、积节点的差异化并行处理。它不仅为概率电路的高性能计算提供了全新的硬件解决方案,更为新兴可处理概率模型的 “缩放定律” 开辟了硬件视角的新路径,在无损压缩、语言建模、生物信息学等领域拥有广阔的应用前景。
论文共同第一作者包括北京大学人工智能研究院博士生范安骏逸、刘雪洁,新加坡国立大学助理教授刘安吉;通讯作者包括燕博南、梁一韬。


