A recent paper titled "Understanding Embodied Reference with Touch-Line Transformer" was published in ICLR 2023. This research has brought about a revolutionary understanding of pointing gestures in the fields of computer vision and robotics, allowing robots to interact with humans more effectively by learning touch-originated pointing gestures.
When robots engage with humans, they often encounter difficulties in determining the objects people are pointing at. This challenge arises because most modern learning algorithms inadequately consider both the gesture and language aspects when interpreting human pointing gestures.
Despite previous attempts (Chen et al., 2021) to explicitly incorporate human posture and language, robots were only able to accurately identify the pointed object in 14% of cases (IoU > 0.75).
One possible factor that may influence the performance of the aforementioned model is the inadequate representation of human pointing gestures. In contemporary computer vision, human body pose is commonly represented using the COCO (Lin et al., 2014) definition. This representation comprises a graph with 17 nodes (keypoints) and 14 edges (connecting the keypoints). While the COCO representation includes connections between the elbow and wrist, it does not encompass a direct connection from the eyes to the fingertips.
The use of the COCO representation, as illustrated in Figure 1, allows us to derive the red line (elbow-to-wrist line). However, it fails to capture the green line (touch-line) connecting the eyes to the fingertips.

Figure 1: The indicated object (microwave oven) is on the touch-line (green) but not on the elbow-to-wrist line (red).
There is a widespread misconception among humans regarding pointing gestures (Herbort & Kunde, 2018): many individuals mistakenly assume that the object being pointed at lies along the red elbow-to-wrist line. In the case of Figure 1, a significant number of people would erroneously rely on this line to determine the pointed object and mistakenly identify the refrigerator as the target.
Using the red elbow-to-wrist line, as depicted in Figure 1, to locate the pointed object is fundamentally flawed. Although this approach has been used in previous computational methods, it is incorrect.
Through extensive observations, it has been discovered that the green touch-line (the line connecting the eyes to the fingertips) provides a more accurate indication of the direction toward the pointed object. In Figure 1, the person is pointing at the microwave oven (as indicated by their verbal mention of "microwave oven" while pointing). The green touch-line intersects the center of the microwave oven, precisely indicating the direction of the referred object. Therefore, incorporating the touch-line can significantly enhance the accuracy of determining the pointed object.
A psychology research study published in Science Advances by O'Madagain et al. (2019) offers compelling evidence supporting the notion that the touch-line aids in accurately locating the pointed object. This study found that the touch-line better reflects the direction of the pointed object and introduced the concept of "embodied reference through touch" in human pointing gestures.
Inspired by this fundamental observation that the touch-line is more reliable than the elbow-to-wrist line, our goal is to enable robots to learn this touch-originated pointing gesture for improved human interaction. Consequently, we have expanded the existing COCO representation of human body pose by incorporating a direct connection between the eyes and fingertips. Our experimental results demonstrate that training the model to learn the touch-line significantly enhances the accuracy of understanding human pointing gestures.
To accomplish this, we have developed a framework comprising a multimodal encoder and a Transformer decoder. We employ cosine similarity to measure the alignment between objects and the touch-line. Additionally, we introduce a referent alignment loss to encourage the model to predict the referred object with a high alignment to the touch-line.
Our method surpasses state-of-the-art approaches by 16.4%, 23.0%, and 25.0% at IoU thresholds of 0.25, 0.50, and 0.75, respectively (Table 1). Specifically, our model outperforms visual grounding methods (Yang et al., 2019; 2020) that do not explicitly incorporate non-linguistic gesture signals. Furthermore, our approach outperforms the method proposed in YouRefIt (Chen et al., 2021), which does not leverage touch-lines or transformer models for multimodal tasks.
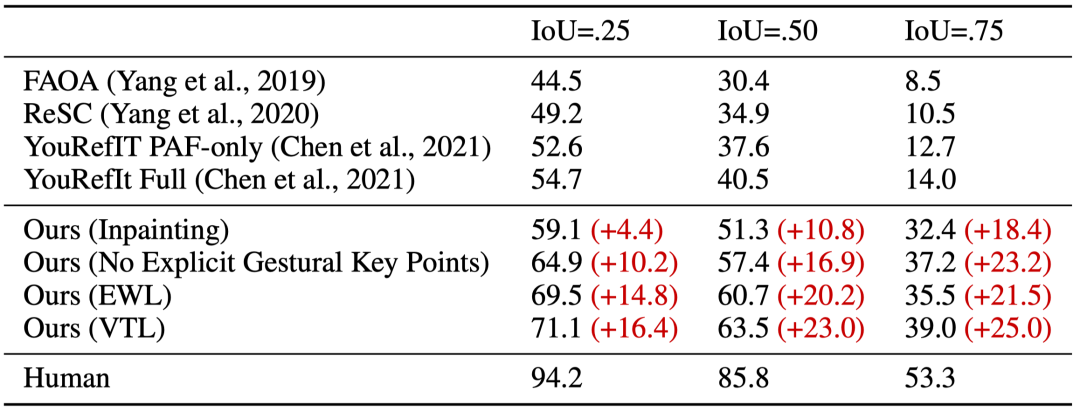
Table 1: Comparison with state-of-the-art methods
Additionally, we conducted a performance comparison among three models: one that explicitly predicts the touch-line, one that explicitly predicts the elbow-to-wrist line, and the last one that does not predict any gesture signals. Across all three IoU thresholds, the model trained to predict the touch-line consistently outperforms the model trained to predict the elbow-to-wrist line (Table 2). Notably, at the IoU threshold of 0.75, the model trained to explicitly predict the elbow-to-wrist line performs worse than the model that does not incorporate any gesture signals.
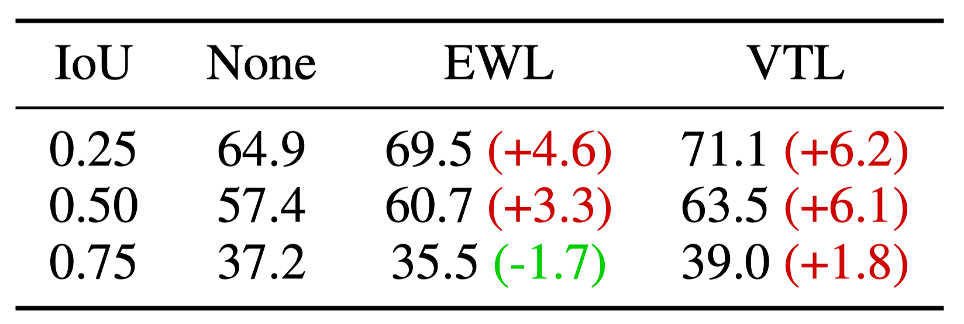
Table 2: Comparison between models predicting touch-line and models predicting elbow-to-wrist line. (None: No explicit prediction of touch-line or elbow-to-wrist line; EWL: Explicit prediction of elbow-to-wrist line; VTL: Explicit prediction of touch-line)
Furthermore, our qualitative findings provide strong evidence that the model trained to predict the touch-line consistently outperforms the model trained to predict the elbow-to-wrist line in numerous instances (Figure 2).

Figure 2: Qualitative Results: The model trained to predict the touch-line performs better in many cases
We present a computational model that learns the touch-line to enhance the understanding of human pointing gestures. Our model takes visual and textual features as input, predicting both the bounding box of the indicated object and the touch-line vector. By leveraging the touch-line prior, we introduce a geometric consistency loss function that promotes collinearity between the referred object and the touch-line. Learning the touch-line yields a substantial improvement in model performance.
Experiments conducted on the YouRefIt dataset showcase that our approach achieves a remarkable +25.0% accuracy enhancement at the 0.75 IoU threshold, narrowing the performance gap between the computational model and human performance by 63.6%. Moreover, our computational model validates the findings of prior human experiments, demonstrating that learning the touch-line enables superior localization of the referred object compared to learning the elbow-to-wrist line.
Authors: Yang Li, Xiaoxue Chen, Hao Zhao, Jiangtao Gong, Guyue Zhou, Federico Rossano, Yixin Zhu


