A paper titled "Accurate yet Efficient Stochastic Computing Neural Acceleration with High Precision Residual Fusion" was presented at the prestigious Design, Automation and Test in Europe (DATE) conference in 2023. The paper proposes a deep neural network (DNN) accelerator based on stochastic computing (SC), which enhances inference accuracy (by 9.43%) by fusing high-precision residual connections in low-precision SC convolution operations. Furthermore, this approach achieves almost no additional hardware overhead (only 1.3%).
With the continuous development of deep learning, DNN model has been widely applied in intelligent Internet of Things (IoT) devices for tasks such as image recognition, video processing, and natural language processing. However, as DNN models become more complex, the increasing number of network parameters and computations poses challenges for edge devices with limited computational and storage resources. SC, a probabilistic computing method that utilizes bit streams instead of traditional binary encoding, has the potential to achieve high area efficiency and excellent fault tolerance in arithmetic circuits, making it suitable for DNN acceleration in edge computing.
There have been several studies on using SC for network acceleration, where researchers have significantly improved the performance of SC-based networks by optimizing multipliers or the overall circuit. However, previous work still faced the inherent trade-off between inference efficiency and accuracy: increasing arithmetic precision can enhance inference accuracy but exponentially increases hardware computation cost, while reducing arithmetic precision can improve computational efficiency but directly reduces inference accuracy.
As shown in Figure 1, low-precision SC circuits using short bit streams (e.g., 2 bits) are highly efficient but result in a 10% decrease in accuracy. On the other hand, longer bit streams can improve precision but come with 3 to 10 times higher hardware overhead.
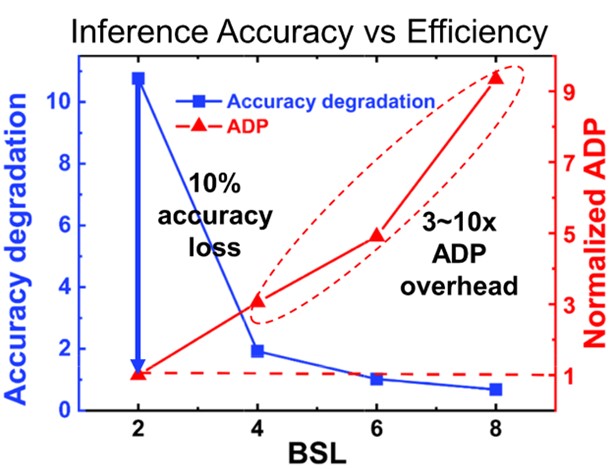
Figure 1. Trends of SC inference accuracy and circuit efficiency with varying bit stream lengths.
To address the challenge of balancing DNN inference accuracy and hardware efficiency in SC circuits, the work described in this paper focuses on quantizing the weights and activations of ResNet18 on CIFAR10 and delves into their impact. The results show that quantizing the activation values significantly affects network accuracy, making low-precision activation values the main bottleneck. Therefore, the work proposes to co-optimize the NN model and the SC circuit design to develop an accurate yet efficient SC NN accelerator.

Figure 2. Quantifying model parameters and activation values separately to identify the bottleneck of accuracy in low-precision networks, namely the low-precision activation values.
In terms of the NN model structure, the work introduces a novel architecture that combines high-precision residuals with low-precision datapaths. By keeping the computationally intensive convolution operations in lower precision, overall hardware efficiency is ensured. At the same time, high-precision residual connections are introduced to greatly improve the inference accuracy. The architecture further fuses the batch normalization (BN) and activation function to enhance SC inference efficiency.
In the circuit aspect, the work analyzes the accumulation logic of different precision bit streams and proposes a high-precision residual module that matches the scaling factor for residual bit streams. Additionally, a function module for fused activation is introduced, which enables BN, ReLU activation, and output quantization to be implemented simultaneously.

Figure 3. The proposed SC-friendly low-precision quantized NN and its required circuit support.
Based on these innovative technologies, the research team compares the proposed high-precision residual design with a baseline accelerator design. The results show that, compared to the original design focusing on circuit efficiency, our design achieves a 9.4% increase in inference accuracy with only 1.3% hardware cost. Compared to the original design focusing on accuracy, the proposed high-precision residual design improves circuit efficiency by three times while maintaining comparable accuracy.
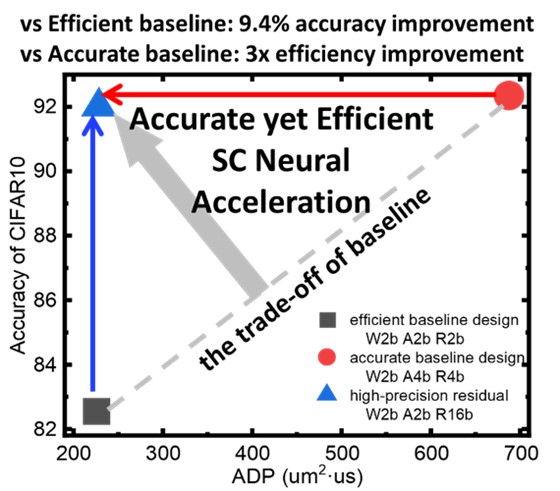
Figure 4. NN/SC circuit co-optimized design balancing inference accuracy and efficiency.
In summary, the research conducted by Assistant Professor Meng Li and Professor Runsheng Wang's team at Peking University proposes a novel NN/SC circuit co-optimized design. This design enhances inference accuracy while maintaining hardware efficiency, which holds significant implications for the application of SC in edge computing NN accelerators.
The first author of the paper is Hu Yixuan, a Ph.D. student from School of Integrated Circuits, Peking University, under the guidance of Assistant Professor Meng Li and Professor Runsheng Wang.


