Research paper titled "MEWL: Few-shot multimodal word learning with referential uncertainty" was present at ICML 2023 recently. This research designs word learning tasks in machines to assess their ability to learn words under the same conditions as humans. MEWL is intuitive and supports these fundamental elements of vocabulary learning and broader human learning.
Word learning is considered one of the most fundamental building blocks of multimodal understanding and reasoning. Inspired by children's capability of few-shot word learning, we constructed MEWL (MachinE Word Learning) to assess how machines learn the meanings of words grounded in visual scenes. MEWL's nine tasks cover core cognitive toolkits in human word learning: cross-situational reasoning, bootstrapping, and pragmatic learning.
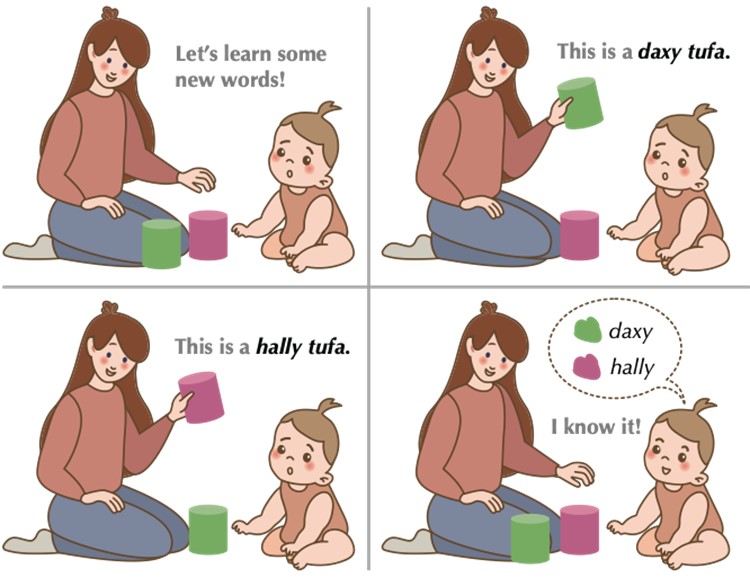
Fig 1: Children can acquire a novel word after only few exposures using cross-situational information, even with referential uncertainty. In this example, a child induces that daxy refers to the color green and hally magenta, all from the experience of a daxy tufa (green cylinder) and a hally tufa (magenta cylinder) without explicit guidance.
Learning words and language is one of the most fundamental stages of human cognitive development, laying the foundation for other key capabilities afterwards, such as learning new object categories, forming abstractions of conceptual structures, making generalizations, and developing the ability to communicate (Lake & Murphy, 2021; Murphy, 2004; Smith & Gasser, 2005; Tenenbaum et al., 2011). Remarkably, we are able to grasp the meanings of words rapidly and effortlessly, even without explicit feedback (Bloom, 2001). One striking observation is that young children can understand the meaning of a novel word from just a few examples, also known as fast mapping, (Carey & Bartlett, 1978; Heibeck & Markman, 1987), with a child can learn about 12 new words per day by the age of eight (Bloom, 2002). These rapidly learned words form our understanding of the world and are the basis of symbolic representations for concepts. learning is inherently few-shot and open-ended. Even without explicit guidance, (Landau et al., 1988; Lake et al., 2015), children encounter considerable referential uncertainty when learning new words, yet they are still able to establish mappings between words and their referents, see Fig. 1 for an illustration. How can we learn so many words from so little? Previous developmental studies has shown that these abilities are composed in multiple ways:
We learn words from co-occurrence across multiple contexts (Scott & Fisher, 2012). Children are little statisticians; (Gopnik et al., 1999; Abdulla, 2001); they employ cross-situational statistics (Smith & Yu, 2008) and perform Bayesian-like inference (Tenenbaum, 1998) to grasp meanings of words from multiple scenes (Xu & Tenenbaum, 2007).
We leverage semantic and syntactic cues to bootstrap novel word learning (Quine, 1960; Pinker, 2009). For instance, we can use familiar relational words to infer the meaning of an unknown word: hearing beef and dax, we can infer dax is a noun, likely edible; it may represent a food similar to beef.
We understand meanings of words with pragmatics, a social account of word learning with the help of other speakers. The fundamental premise is to leverage informative descriptions of the referent (Frank & Goodman, 2014; Horowitz & Frank, 2016; Stacy et al., 2022). For example, if we have a blue cube, a blue ball, and a green cube in a line, a speaker would use the word “ball” to refer to the object in the middle, which is the most informative word to tell them apart (Frank & Goodman, 2012).
Human-like word learning is critical for building machines that learn and reason like people (Lake et al., 2017; Zhu et al., 2020; Fan et al., 2022). Despite recent progress in language-only and vision-language pre-training, it remains unclear whether these models acquire word meanings in human-like ways (Lake & Murphy, 2021; Bender & Koller, 2020; Mitchell & Krakauer, 2023). Concerns have been raised that the pre-training paradigm fails to capture core ingredients of human language and conceptual structure, such as compositionality (Thrush et al., 2022), concept association (Yamada et al., 2022), relational understanding (Conwell & Ullman, 2022), and conceptual meaning (Piantasodi & Hill, 2022). These concerns can be linked to differences in how humans and machines acquire the primitives of words (Fodor et al., 1988; Tenenbaum et al., 2011). To the best of our knowledge, a systematic and rigorous evaluation is still missing for human-like word learning in machines.
To fill this gap, we devised the MachinE Word Learning (MEWL) benchmark to assess how machines learn word meanings in grounded visual scenes, covering human’s core cognitive toolkits in word learning. MEWL serves as a testbed for few-shot vision-language reasoning with referential uncertainty. It includes nine tasks covering four types of scenarios: basic attribute naming, relational word learning, number word learning, and pragmatic word learning.
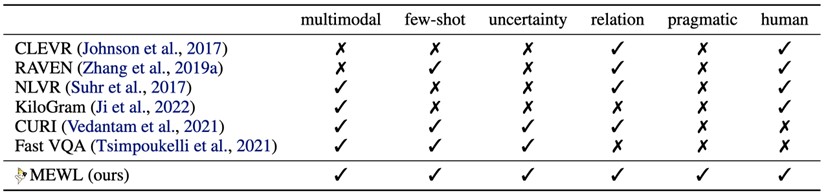
Fig 2: Comparison of MEWL with prior work. We compare MEWL with related benchmarks in six dimensions including multimodality, few-shot, referential uncertainty, relational reasoning, pragmatic reasoning, and human baseline.
In creating MEWL, we draw inspiration from and correspondingly highlight these methods in human word learning: cross-situational learning, bootstrapping, and pragmatic word learning. We designed nine unique tasks in MEWL for comprehensive evaluate alignment between humans and machines: shape, color, material, object, composite, relation, bootstrap, number, and pragmatic. These tasks cover various aspects:
Learn novel words or phrases representing basic object attributes (i.e., shape, color and material), the objects per se (i.e., object), and composition of basic attributes (i.e., composite) (Fig. 3).

Fig 3

Fig4
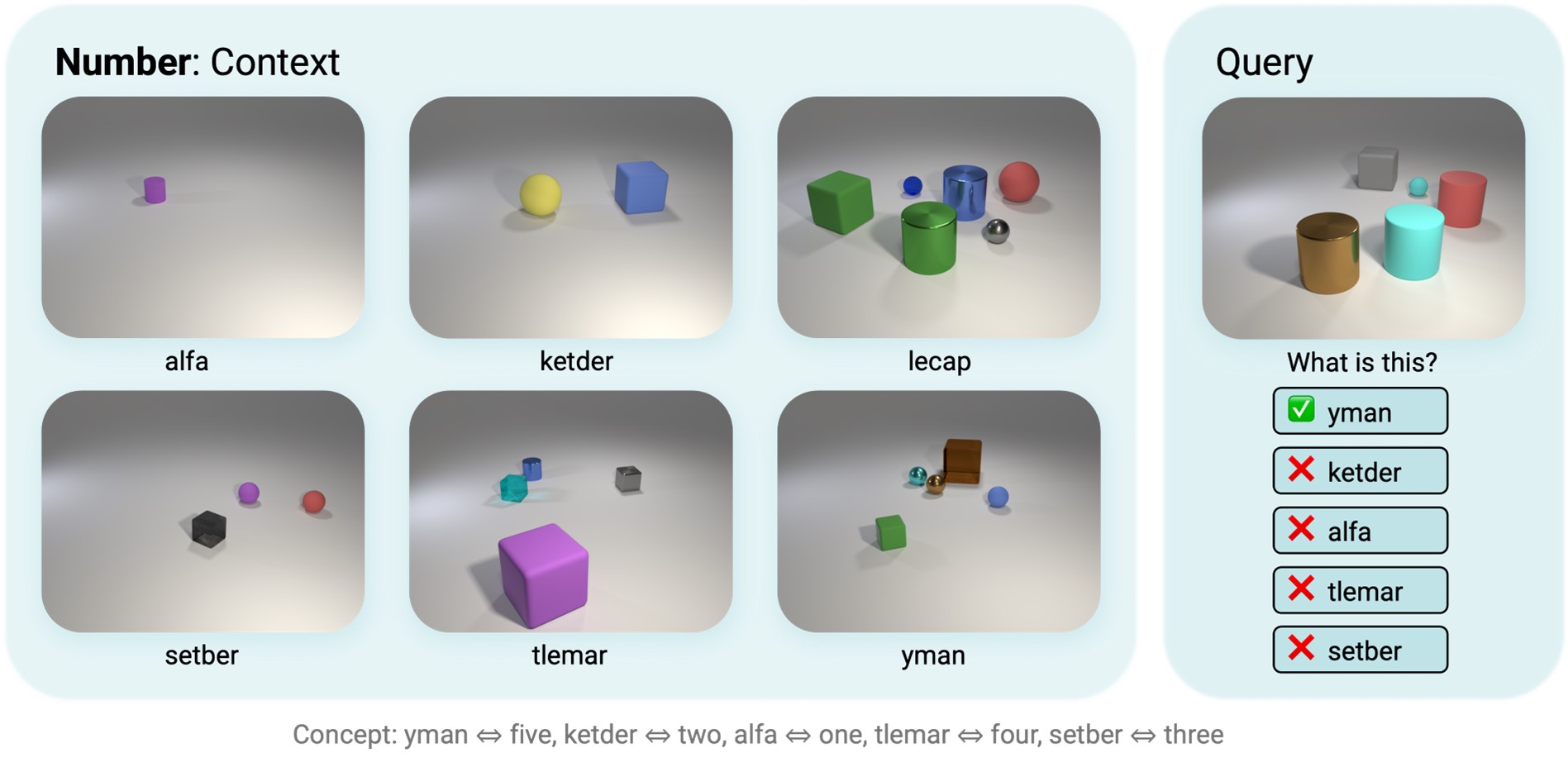
Fig 5
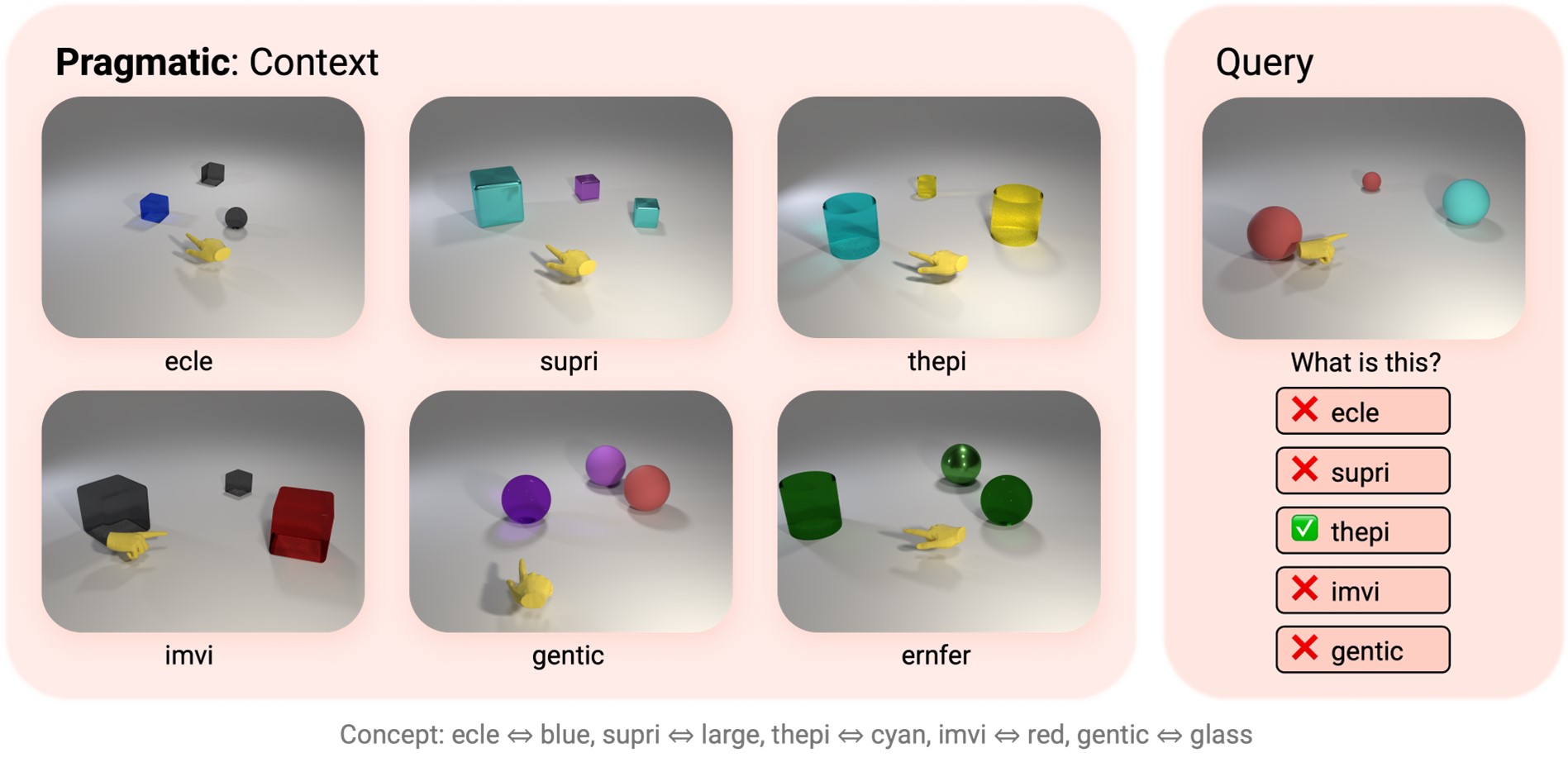
Fig 6
Figs 3-6: Each episode consists of six context images and corresponding utterances. Agents need to choose the correct utterance matching the query image out of the given five options based on cross-situational reasoning from the six context panels. Ground-truth word-to-concept mappings are listed below examples.
These tasks are designed to align with core building blocks of human word learning, and echo the theories in the developmental literature (Carey & Bartlett, 1978; Pinker, 2009; Bloom, 2002; Scott & Fisher, 2012; Smith et al.,2011; Horowitz & Frank, 2016; Frank & Goodman, 2014). As such, MEWL constitutes a comprehensive suite for probing how machines learn the meaning of words from various few-shot scenarios with referential uncertainty. In MEWL, all nine tasks involve referential uncertainty at varying extents and must be resolved from cross-situational disambiguation. We use the same referential uncertainty concept defined in previous word learning literature: “For any heard name, there are many candidate referents with variable perceptual properties” (Yu et al., 2021).
To probe human-like word learning in artificial agents, we examine contemporary models on MEWL. Formulating MEWL as a few-shot vision-language learning problem, we choose models that fall into two categories: multimodal (vision-language) and unimodal (language-only) models. We also evaluated humans to provide the average human baseline.
For multimodal models, we chose CLIP (Radford et al., 2021), Flamingo-1.1B (Alayrac et al., 2022), and Aloe (Ding et al., 2020). For language-only models, we used GPT-3.5 (Brown et al., 2020) and BERT (Devlin et al., 2018). We tested models based on a “caption then classify” paradigm. First, we use a task-specific oracle annotator to parse the input visual scenes into a scene description. Next, we use the language models to classify the result as a multiple choice question. Notably, these annotations are injected with the precise inductive biases needed to solve these tasks, containing less uncertainty and ambiguity than images used in multimodal models. This design greatly simplifies the task difficulty, since mapping patterns in annotations to answers is easier for language-only models. Specifically, inspired by Yang et al. (2021), we prompted GPT-3.5 with zero-shot multi-choice templates based on the full annotations generated for context scenes and queries. We also fine-tuned BERT models on the true annotations, learning mappings from annotations to answers.

Fig 7: Performance of baseline models and humans on MEWL.
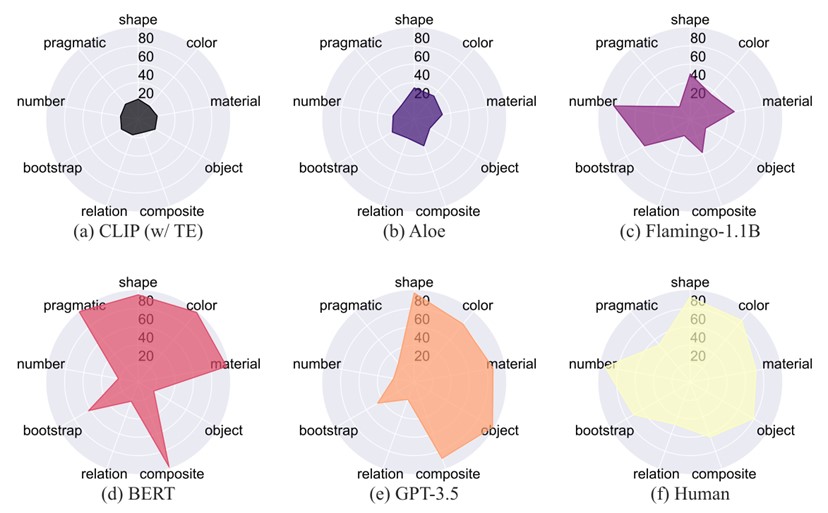
Fig 8: Visualization of agents’ performance on MEWL
Performance of Multimodal Models
Overall, the best vision-language model is Flamingo-1.1B (41.0%), which is about half of human ability (73.2%). Meanwhile, a vanilla Transformer model with CLIP features performs only at chance level (below 20%) across all tasks. The object-centric representations in Aloe help improve performance to 26.8%, but may perform worse due to limited model capacity and lack of pre-training.
Looking deeper into task-specific results, we find vision-language pretrained models perform relatively well on basic attribute naming tasks (i.e., shape, color, material) but fail to generalize to object relations and leveraging pragmatic cues for inference. An interesting observation is that the Flamingo model can solve a small portion of bootstrap tasks and some number tasks. This result may be attributed to the Flamingo model being language-model-based, capturing syntactic cues and understanding familiar words to bootstrap word learning.
Performance of Unimodel Models
For language-only models, fine-tuned BERT has the best overall performance, averaging 68.3%. BERT and GPT-3.5 perform well on object-level tasks (i.e., shape, color, material, object, composite, bootstrap) but fail on tasks requiring understanding more complex relationships beyond one-to-one mappings (i.e., relation, number). Fine-tuning on the training set also allows the BERT model to perform well on pragmatic tasks, while GPT-3.5 (without fine-tuning) fails, indicating some capabilities can indeed be learned via task-specific tuning. However, we also want to point out that heavily human-biased detailed annotations have been used: we provide object-centric annotations for basic attribute naming tasks, relative spatial relations for relation tasks, and ground-truth referents for pragmatic tasks. In that sense, the problems are simplified to a translation-like problem, sidestepping challenges of conceptual abstraction in human word learning.
Multimodal vs. unimodal
In comparing multimodal models (i.e., CLIP, Flamingo, Aloe) and unimodal models (i.e., GPT-3.5, fine-tuned BERT), we observe text-based models with ground-truth text annotations (captions) generally outperform models based on visual inputs. This observation in machines seems counter-intuitive as it contrasts with the empirical observations and computational studies on human multimodal learning, which argue that multi-modality boosts the acquisition of words and concepts (Clark, 2006; Smith & Gasser, 2005). Why and how do contemporary unimodal agents outperform multimodal ones in few-shot word learning? We present some preliminary discussions on this phenomenon in the following.
First, we believe that part of the conceptual role, not all of it, in unimodal language models may be acquired in a way different from humans. Recently, some studies have shown that large language models can encode human-like conceptual structures, even perceptual ones, from unimodal training data (Piantasodi & Hill, 2022; Abdou et al., 2021), which are confirmed by experiments on human neural systems (Bi, 2021). In our experiments, GPT-3.5 succeeds in achieving comparable performance to humans on some basic attribute naming tasks (i.e., color, material, shape, object, composite) but fails to learn complex relational words (i.e., number, relation), indicating it already has some conceptual knowledge of shapes, colors, and materials from unimodal training. Nevertheless, GPT-3.5 fails in learning with pragmatic cues, supporting arguments that text-based models cannot infer communicative intents without perceptual grounding (Lake & Murphy, 2021). This calls for pursuing perceptually grounded word learning in machines, which our MEWL contributes to.
Second, the unimodal version of MEWL is similar to the “Quine’s Gavagai problem” (Quine, 1960). Since we use ground-truth captioners specifically designed for each task, unimodal language models do not need to undertake the original word learning through concept induction like humans. Instead, they acquire meanings of novel words through few-shot translation from familiar English vocabulary, greatly reducing the difficulty and ambiguity of multimodal word learning. In other words, the unimodal setting is not comparable to the multimodal setting. From experiments on fine-tuned BERT models, some tasks that do not require complex cross-situational reasoning can be solved with satisfactory performance. By simplifying the problem to unimodal translation, fine-tuning unimodal models transforms it into a pattern recognition problem, finding hidden statistical patterns from the training data without acquiring actual human-like few-shot word learning capabilities. Therefore, we suggest future work should not perform specific fine-tuning on the unimodal caption version of MEWL to improve performance, but rather use it for comparing unimodal and multimodal models.
Based on 217 valid responses, our human studies demonstrate MEWL is well-designed, reflecting core cognitive skills humans use for word learning. For example, we observe humans perform decently on basic naming tasks, with performance ranking as shape ≈ color > material > composite, consistent with previous psychological findings of shape bias (Landau et al.,1988) and fast mapping (Heibeck & Markman, 1987). Humans are also effortless in counting. The relational and pragmatic learning tasks are more challenging than other tasks; relational words typically lack object referents and are also considered acquired later in development (McCune-Nicolich, 1981; Gentner, 2005). Our human studies provide key references for the level of human-like word learning that should be exhibited on MEWL.
Few-shot learning is one of the most fundamental multimodal reasoning abilities of humans; it is the first step of language acquisition and facilitates learning concepts (Clark,2006). Despite recent large-scale vision-language contrastive pre-training (Radford et al., 2021) that can be seen as an approximate form of learning from referential uncertainty, it still diverges greatly from human learning: e.g. failure in social-pragmatic word learning (pragmatic tasks in MEWL and Lake & Murphy (2021)), difficulty in acquiring numerals and relational words (number and relation tasks in MEWL, Radford et al. (2021) and Conwell & Ullman (2022)), inability to understand compositionality (Thrush et al., 2022), and concept association biases (Yamada et al., 2022). These issues indicate current learning paradigms do not understand word meanings in human-like ways, leading to problems of alignment and efficiency. Whether human-like word learning should be a pathway for multimodal AI remains an open debate, but it is a basic capability for human-AI alignment (Yuan et al., 2022).
Word learning represents a general form of human learning. We learn with referential uncertainty while current machines do not. We use cross-situational information to support few-shot learning of words and concepts while current models struggle at this. We learn through teaching and social-pragmatic cues while AI today fail to understand. Before bridging this gap, how can we assess machines' capability of learning words under the same conditions as humans? We take a first step by designing these word learning tasks in machines; MEWL is simple and intuitive to support these basic elements in word learning and, in a broader range, human-like learning.
Guangyuan Jiang, a “TongClass” student, entered Yuanpei College in 2020, Peking University, is the first author of this paper. Guangyuan, Prof. Yixin Zhu from the Institute for Artificial Intelligence at Peking University, and research scientist Dr. Chi Zhang from the Beijing Institute for General Artificial Intelligence are co-corresponding authors. Other co-authors include Manjie Xu from the Beijing Institute for General Artificial Intelligence, Shiji Xin from School of EECS, Peking University, Prof. Wei Liang from Beijing Institute of Technology, and Assistant Prof. Yujia Peng from the School of Psychological and Cognitive Sciences at Peking University.
Paper link: https://sites.google.com/view/mewl


