Human-object interaction understanding [1,2] is important in computer vision and robotics. Enabling AI algorithms to understand complex human-object interactions in 3D space has been a goal pursued by researchers, yet there are still many challenges to achieve this goal.
Firstly, the research community lacks algorithms for full-body involved human interactions with complex objects. Existing methods are mostly limited to interactions with rigid objects [3,4], or only focus on specific body parts. Secondly, real-world objects have complex structures, making them hard to describe with a single template. Recent works have started to study articulated objects [5], but are still limited to one movable part, lacking complex structures and motions. Thirdly, modeling the relationships between humans and objects is also a major challenge now [6]. For example, when leaning backwards, the backrest of a chair would rotate. Such phenomena contain complex 3D structural correlations between humans and objects.
The above challenges are not insurmountable, but the fundamental problem points to the lack of prior knowledge in algorithms. To address this, based on a large number of real interaction cases, including 17.3 hours of human interactions with complex objects, 46 different subjects, 81 interacting objects like chairs, sofas and stools with different shapes, this paper provides fine-grained 3D shape annotations of human bodies and objects. It also provides the original data of multi-view RGB-D, as well as aligned point cloud data after multi-camera calibration. Based on the CHAIRS dataset, this paper proposes a cVAE-based model to obtain human-object interaction priors and guide the processes of object part reconstruction and pose optimization, achieving accurate estimation of part-level 6D poses of articulated objects.
These results were recently published in ICCV 2023 in a paper titled "Full-Body Articulated Human-Object Interaction". The paper is co-authored by Assistant Professor Yixin Zhu from the Institute for Artificial Intelligence, Peking University and Researcher Siyan Huang from the Beijing Institute for General Artificial Intelligence(BIGAI). The goal of this research is to address the problem of complex human-object interaction understanding. The paper proposes an algorithm for fine-grained human-object interaction understanding and reconstruction using full-body interaction 3D priors, and demonstrates applications in downstream vision tasks. The paper also proposes interaction priors based on a large amount of human interactions with articulated objects, and provides real data with fine-grained 3D pose and structure annotations. This work fills the gap of 3D vision methods for full-body complex interactions, laying the foundations for accessible and embodied intelligence research and applications.

Object Reconstruction
This paper solves the problem of reconstructing articualted human-object interactions from a single image. Specifically:
The human body is represented using SMPL-X parameters. If the object model is given, each part of the object is represented using a 6D pose. Without a given model, the object is directly reconstructed in 3D. The object reconstruction model takes the image and estimated human pose as input. It first extracts image features and human voxels at different scales, feeds image features into a 3D deconvolutional network, and concatenates 3D features from each layer with the human voxels. Finally it produces a probability distribution of points occupied by the object in space.
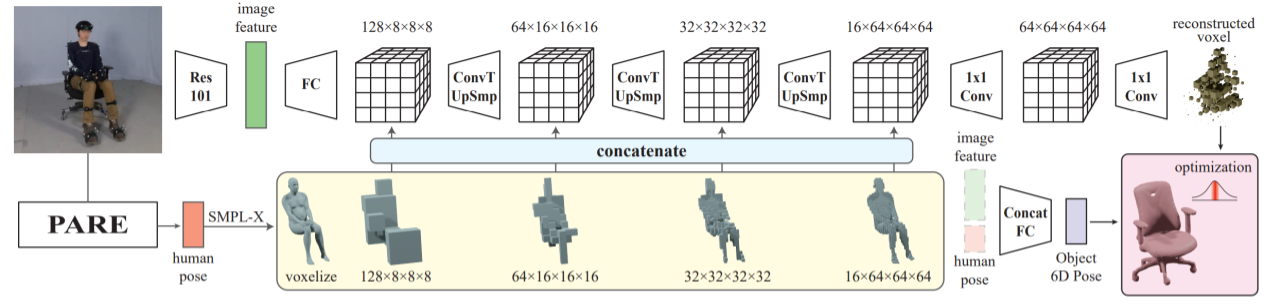
Human-Object Interaction Priors
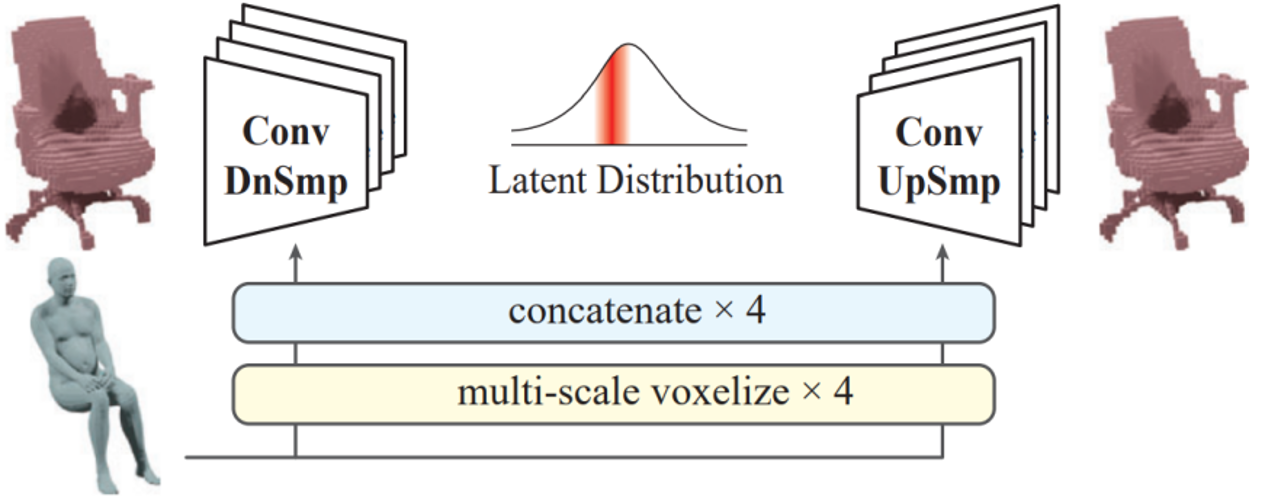
Modeling fine-grained relationships has important value for understanding human-object interactions. This paper proposes an interaction prior model based on cVAE, which learns the 3D spatial distribution of objects given human poses from the large-scale interaction data in CHAIRS. The interaction prior model takes voxelized human bodies as input, and outputs the joint probability distribution of point occupancies in the surrounding space. This modeling approach can infer the most likely object shape given estimated human poses, thus providing necessary guidance for estimating object poses.
Interaction Sequences Collection
Experimental setup: All clips are captured in an area equipped with an inertia-optical hybrid motion capture system, with all motions fully visible to the cameras. Four multi-view Kinect Azure DK cameras facing the performer are arranged around the perimeter after precise calibration and synchronization, acquiring RGB-D information and point clouds.
Object pose collection: First, objects are arranged in their initial poses, and hybrid trackers are attached to each movable part. During the recorded interactions, the 6D poses of each object part relative to the base are computed in real time based on the tracker poses. Finally, rigid fits are made to the object motion structure to obtain high-quality object poses.
Human pose and shape collection: We use the SMPL-X representation for human poses and shapes. Participants wear a motion capture suit equipped with 17 IMUs, a pair of gloves and 5 hybrid trackers mounted on the head, hands and feet during recording. The shape parameters of the human model are optimized during interactions so that the reconstructed SMPL-X meshes align with the hybrid tracker positions. The motion capture system produces real-time estimates of human poses and shapes throughout the recording process.
Experimental Results
To comprehensively evaluate the proposed method, the authors evaluate the proposed reconstruction method on the CHAIRS dataset and images from the web containing persons and chairs. The results show that the proposed method can reconstruct reasonable interaction poses of human bodies and objects from a single image, regardless of whether the 3D object model is given or not.
The first author is Peking University PhD student Nan Jiang (advised by Yixin Zhu) and Researcher Tengyu Liu from the Beijing Institute for General Artificial Intelligence. The corresponding authors are Assistant Professor Yixin Zhu and Researcher Siyan Huang. Other authors include undergraduates Zhexuan Cao and Zhiyuan Zhang from the Dept. of Automation, Tsinghua University, BIGAI intern Jieming Cui, BIGAI researcher Yixin Chen, and Peking University Assistant Professor He Wang.
References:
[1] Zhu Y, Jiang C, Zhao Y, et al. Inferring forces and learning human utilities from videos. In Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Chen Y, Huang S, Yuan T, et al. Holistic++ scene understanding: Single-view 3d holistic scene parsing and human pose estimation with human-object interaction and physical commonsense. In International Conference on Computer Vision (ICCV), 2019.
[3] Taheri O, Ghorbani N, Black M J, et al. GRAB: A dataset of whole-body human grasping of objects. In European Conference on Computer Vision (ECCV), 2020.
[4] Bhatnagar B L, Xie X, Petrov I A, et al. Behave: Dataset and method for tracking human object interactions. In Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
[5] Fan Z, Taheri O, Tzionas D, et al. ARCTIC: A Dataset for Dexterous Bimanual Hand-Object Manipulation. In Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
[6] Zhang J Y, Pepose S, Joo H, et al. Perceiving 3d human-object spatial arrangements from a single image in the wild. In European Conference on Computer Vision (ECCV), 2020.


