Artificial intelligence, represented by deep learning, is being widely applied across various industries. Due to the enormous parameter and computational requirements of deep neural networks (DNNs), existing deep learning services are often deployed in the cloud and rely on users uploading plaintext data directly, posing serious risks of data leakage. Therefore, safeguarding data and model privacy during deep learning inference is crucial. However, existing private inference solutions face significant communication overhead, making the effective reduction of communication overhead an urgent problem.
The team led by Li Meng at Peking University has reduced the communication overhead of private inference by nearly 4 times through collaborative optimization of neural network architecture and private inference protocols. This work has been published at NeurIPS 2023.

Paper Link: https://arxiv.org/pdf/2311.01737.pdf
In this research, we emphasize the equal importance of pre-processing and online stages in private inference and propose CoPriv, a collaborative optimization framework of neural network architecture and private inference protocols. Firstly, CoPriv optimizes the commonly used 3x3 convolutions based on the Winograd algorithm and introduces a series of optimization schemes. For lightweight mobile networks like MobileNetV2, we propose differentiable ReLU pruning and network re-parameterization techniques. Compared with existing research, our work optimizes both linear layers (convolutions) and non-linear layers (ReLU and truncation) to simultaneously improve the communication efficiency of pre-processing and online stages. The following diagram illustrates the complete collaborative optimization framework and demonstrates the benefits brought by various optimizations using ResNet-18 and MobileNetV2 as examples.
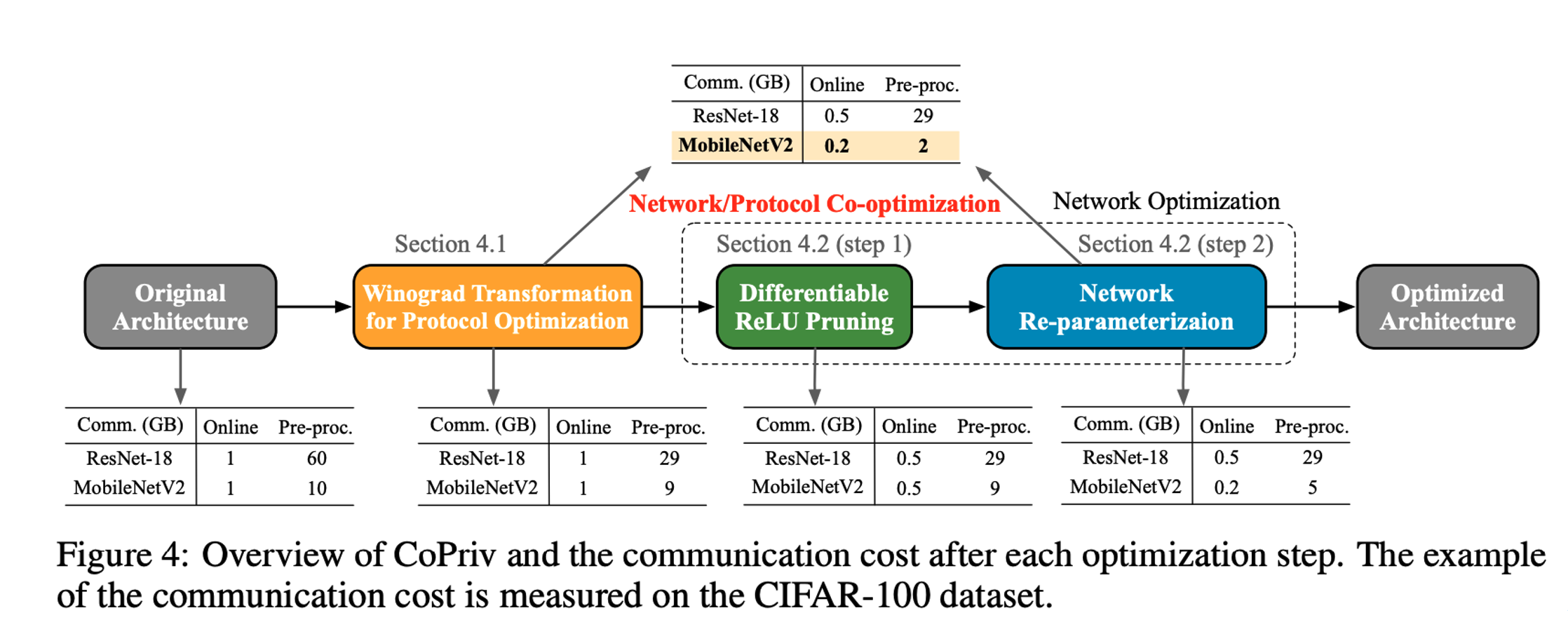
Inference Protocol Optimization
Through our analysis, we found that the communication overhead of convolutions is directly related to the number of multiplications. Since the total communication overhead is dominated by the multiplications in convolutions, our core approach involves reducing the total number of multiplications at the cost of increasing local additions (local additions do not require communication in secure multiparty computation) to reduce the total communication overhead.
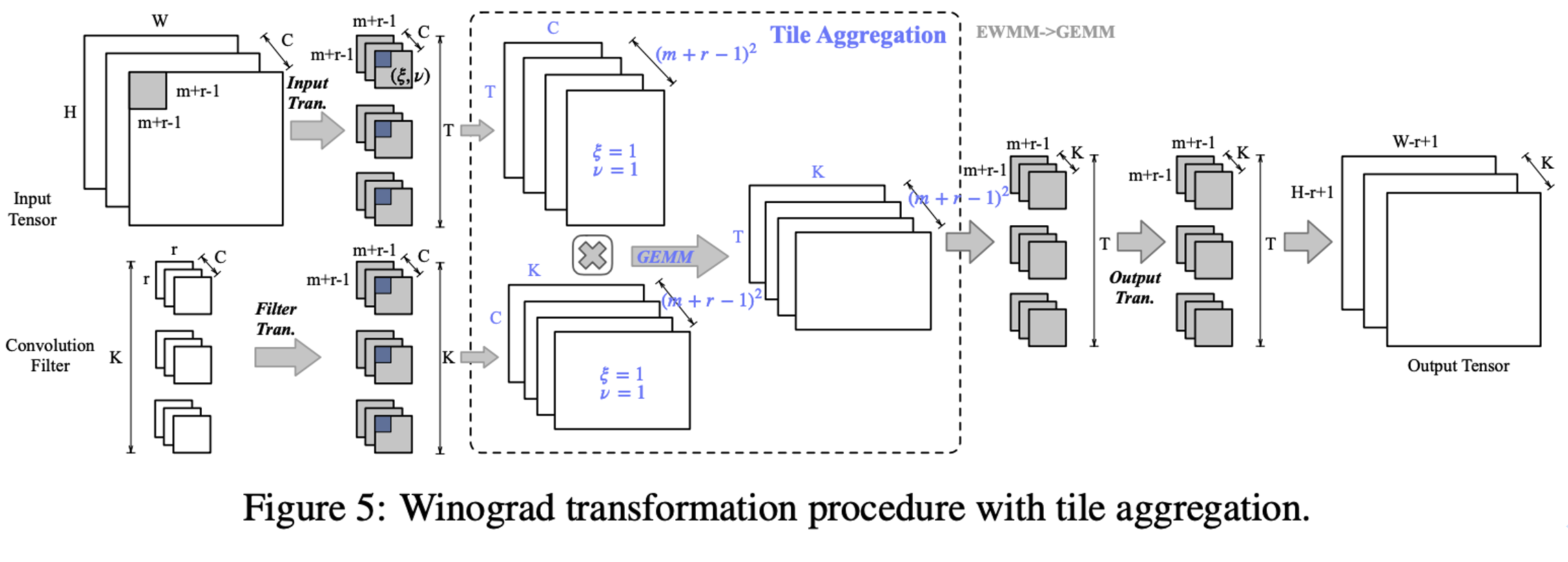
Optimization 1: Tile Aggregation Technique
While the Winograd transform helps reduce the number of multiplications, the original element-wise matrix multiplication (EWMM) cannot leverage batch optimization based on oblivious transfer protocols used in private inference, leading to expensive overheads. Hence, we propose the tile aggregation technique to transform EWMM into the form of general matrix multiplication (GEMM) to reduce communication overhead. The convolution protocol and computational process are illustrated in the following diagram.
Optimization 2: Adaptive Convolution Technique
During the execution of the convolution protocol, both the server and client (as the sender in oblivious transfer) can initiate the protocol. As the dimensions of input feature maps and filters differ, we observe that the initiator's selection affects the number of communication rounds and communication complexity. CrypTFlow2 always chooses the server to initiate the protocol, while our proposed neural network architecture-aware convolution protocol dynamically selects between the server and client based on layer dimensions to maximize the reduction in communication complexity.
The communication complexity analysis of different convolution operations is illustrated in the diagram below.
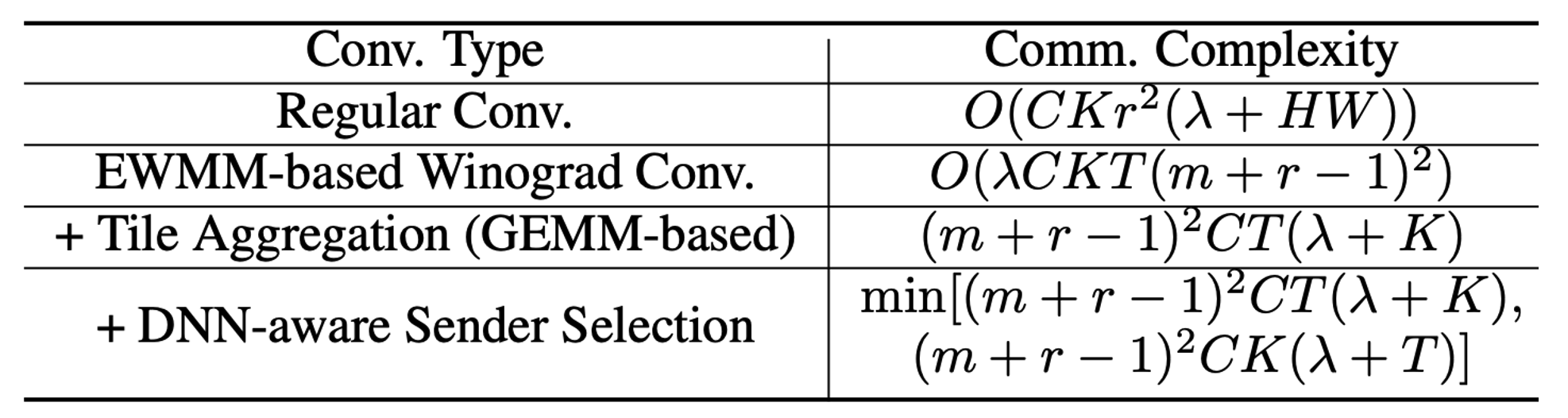
Communication Complexity Analysis of Different Convolution Operations
Neural Network Architecture Optimization
The core idea of this paper is that by removing two ReLUs from the inverted residual block of MobileNetV2, the entire residual block can be fused into a single convolutional layer and further optimized through the Winograd transform-based protocol.
Issue 1: How to Remove ReLU?
To identify "unimportant" non-linear activation functions (ReLU), we propose a communication-aware differentiable ReLU pruning algorithm. CoPriv assigns an architecture parameter α to each ReLU to measure its importance. During pruning, each activation function follows the calculation: α · ReLU (x) + (1-α) · x, optimizing both model weight parameters θ and architecture parameters α simultaneously. To ensure CoPriv's pruning focuses on layers with higher communication overhead, we define a loss function with communication-aware regularization.
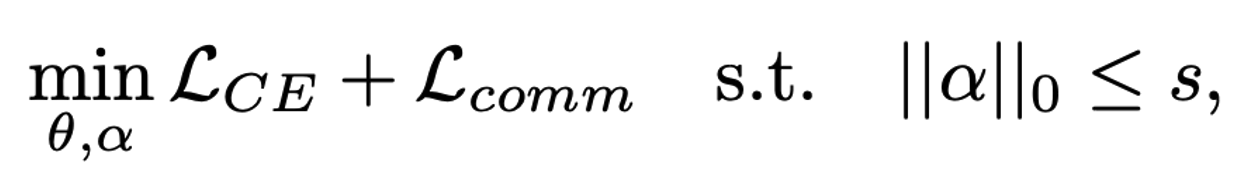
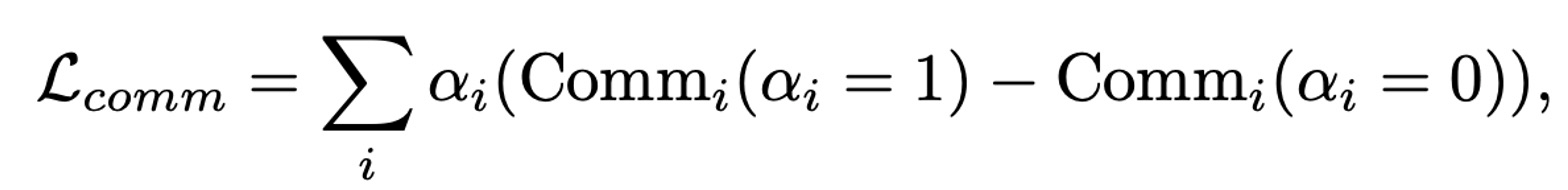
To ensure the entire inverted residual block can be further fused, we let two ReLUs share the same architecture parameter during pruning, as illustrated in the diagram below.
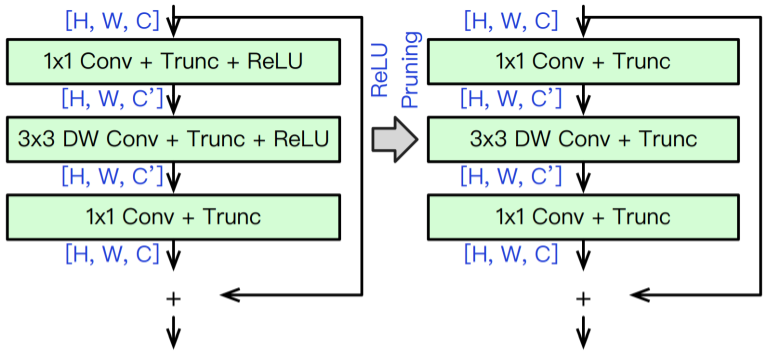
Process of ReLU Pruning Algorithm
Issue 2: How to Fuse Residual Blocks?
Network (structural) re-parameterization is an optimization technique to accelerate neural network inference. Its core idea is to decouple the network architecture during training and inference while ensuring both architectures are completely equivalent (achievable through parameter fusion). This ensures the network has high performance during training and high efficiency during inference.
For CoPriv, after removing "unimportant" ReLUs, the inverted residual block becomes a linear structure. Thus, through network re-parameterization, Point-wise convolutions and Depth-wise convolutions can be fused into a single dense convolutional layer, as illustrated in the diagram below.
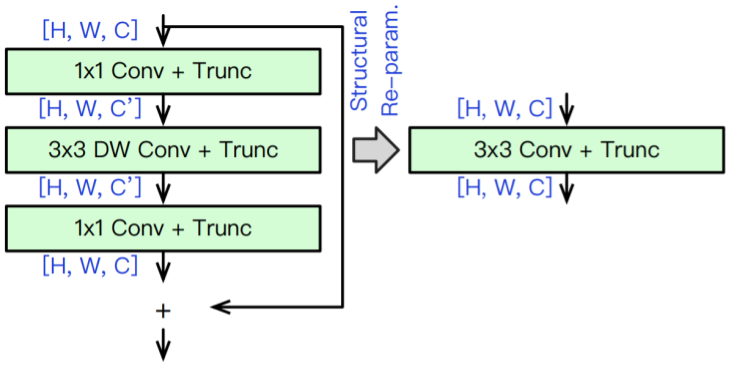
Process of Network Re-parameterization Algorithm
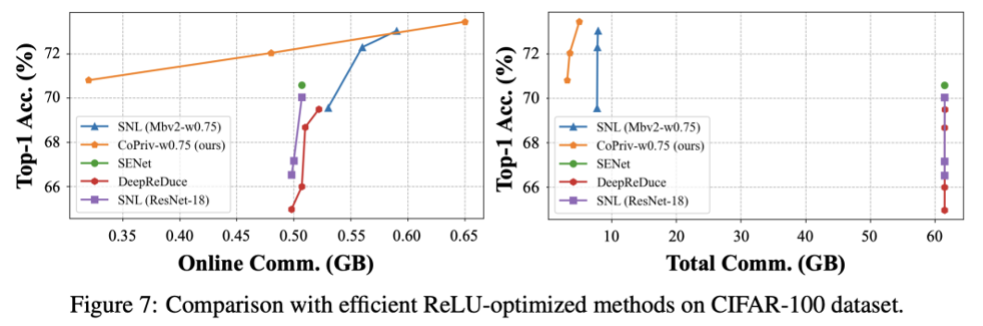
As shown in the diagrams below, we conducted experiments on the CIFAR-100 and ImageNet datasets, demonstrating that CoPriv surpasses baseline methods in accuracy and online/total communication overhead. Additionally, existing ReLU optimization works such as DeepReDuce, SNL, and SENet fail to effectively reduce total communication overhead.
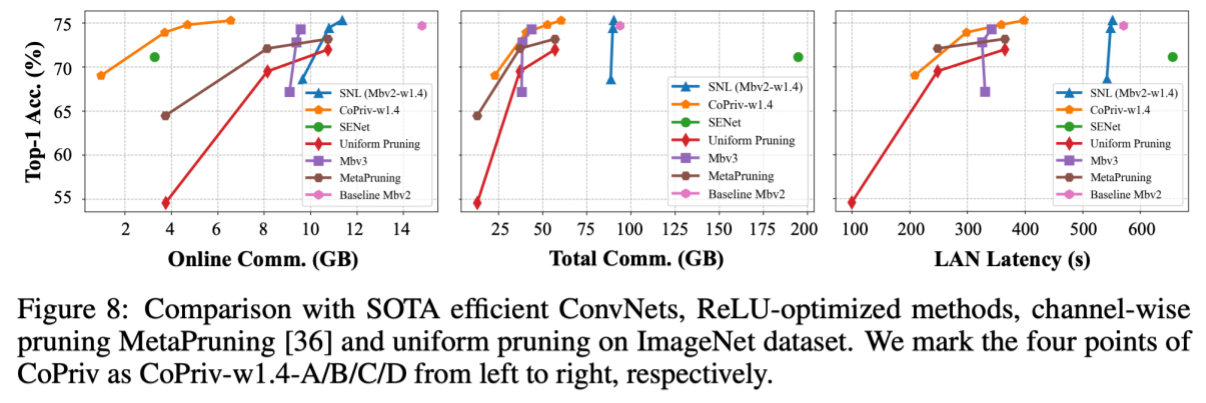
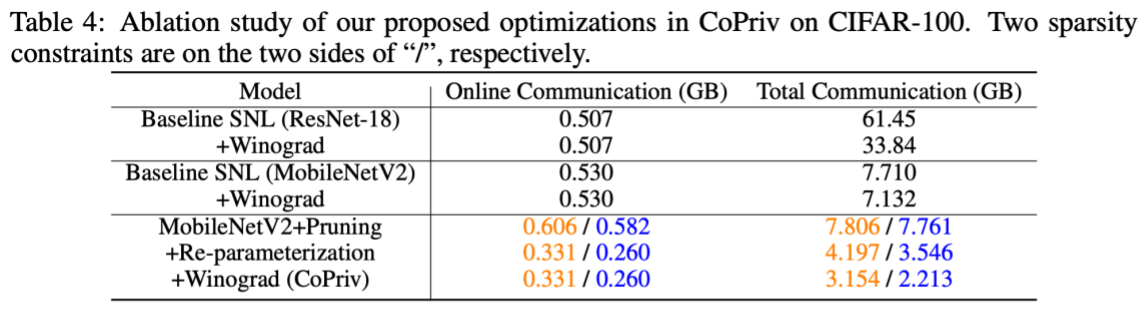
Furthermore, we performed ablation experiments on different optimization techniques in CoPriv. The results in the following diagram indicate that our proposed ReLU pruning, network re-parameterization, and Winograd convolution protocol effectively contribute to enhancing the efficiency of private inference.
The first author of this paper is Zeng Wenxuan, a PhD student at Peking University, the corresponding author is Li Meng, the assistant professor at PKU-IAI.


